



The sun shines with the magnetosphere every day so I’m on it. I do work every day and enjoy it. When you don’t have a 9-5 job or a husband, every day is good and different. Nothing is boring. No one is trying to control your time or criticizing and fighting you. I have zero tolerance for that.
As a side note, WP thinks I edit past posts and repost them because I’m fixing it. Not at all. I do edit it and then I repost it because followers are behind the curve in understanding what I’m doing. I started posting on the Time Harmonic 6 years ago. Everyone got caught up in COVID. I didn’t, and never obeyed the mandates. I kept working.
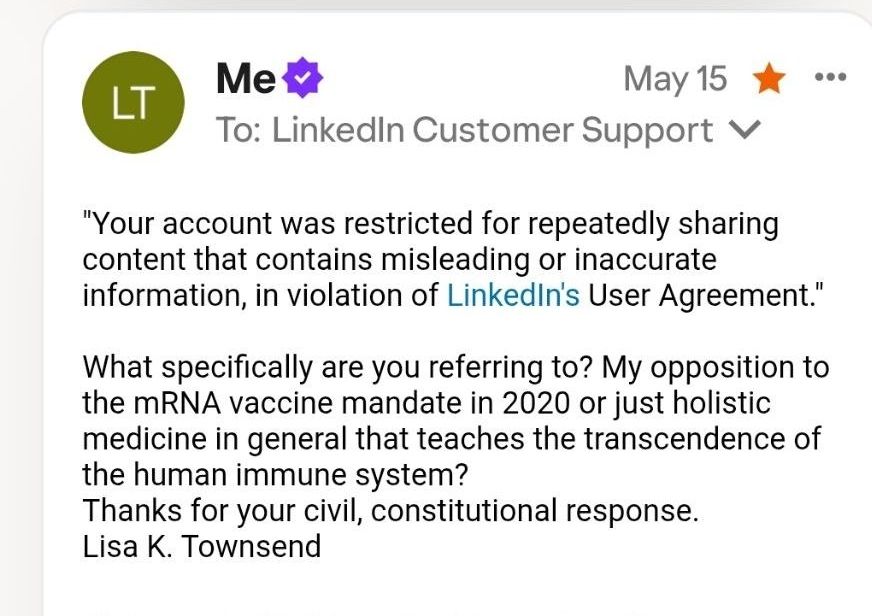
I was kicked off of F…book and LinkedOut. It was because I was vocally opposed to the mRNA vaccine mandate by April 2020 during the lock downs and forced masking. Turns out that all who said they were deadly were correct. Apology accepted. Lol. 👇👇👇

You must be logged in to post a comment.